| 1. | Introduction to C++ |
| 2. | Variables, branching, and loops |
| 3. | Functions and recursions |
| 4. | Pointers |
| 5. | Linked lists |
| 6. | Stacks |
| 7. | Sequences |
| 8. | Pointers practice |
| 9. | References |
| 10. | Sorting |
| 11. | Object oriented programming |
| 12. | Trees in C++ |
| 13. | Balanced trees |
| 14. | Sets and maps: simplified |
| 15. | Sets and maps: standard |
| 16. | Dynamic programming |
| 17. | Vectors |
| 18. | Multi core programming and threads |
| 19. | Representation of integers in computers |
| 20. | Floating point representation |
| 21. | Templates |
| 22. | Inheritance |
| 23. | Pointers to functions |
10. Sorting
1. Monotone arrays
Assume that x[0], x[1], ..., x[n-1] is an array of real numbers, or an array of integers. We say that the array is monotone, if it satisfies one of the following four conditions.
- 1. Non-decreasing:
x[0]\(\leq\)x[1]\(\leq\cdots\leq\)x[n-1]; - 2. Non-increasing:
x[0]\(\geq\)x[1]\(\geq\cdots\geq\)x[n-1]. - 3. Increasing:
x[0]\(<\)x[1]\(< \cdots<\)x[n-1]; - 4. Decreasing:
x[0]\(>\)x[1]\(> \cdots>\)x[n-1].
An array can be increasing only if all of its terms are different. Similarly, an array can be decreasing only if it has distinct terms.
2. Sorting algorithms
We will describe two famous sorting algorithms: bubble sort, and merge sort. Bubble sort is easier to teach and easier for programmers to write. It has very few lines of code. However, it is very inefficient. Merge sort is very efficient and fast. However, merge sort is somewhat painful to write. If the length of an array is \(N\), then the bubble sort has complexity \(O(N^2)\), while the merge sort has complexity \(O(N\log N)\).
Remark: An algorithm has the complexity \(O(N^2)\) if there exist two positive constants \(C_1\) and \(C_2\) such that the execution of the algorithm requires between \(C_1\cdot N^2\) and \(C_2\cdot N^2\) instructions. Similarly, the algorithm has complexity \(O(N\log N)\) if there are constants \(D_1\) and \(D_2\) such that the number of instructions that the algorithm executes is between \(D_1\cdot N\log N\) and \(D_2\cdot N\log N\).
The constants \(C_1\), \(C_2\), \(D_1\), \(D_2\) are not essential for our comparison of the algorithms. These constants are different among different compilers, operating systems, and computers. However, the numbers \(N^2\) and \(N\log N\) are of different orders of magnitude, and that is all that matters. For example, if \(N\) is the total number of humans on Earth, then \(N\approx 10^9\). Bubble sort would take several months to sort all of the names of all of the humans. Merge sort would take a few seconds.
If we wanted to sort all the addresses of all webpages on the internet that exist at the moment, then merge sort would need a few hours. Bubble sort would need thousand years.
3. Bubble sort

The bubble sort algorithm consists of \(N-1\) sub-routines that are called shakings. After the first shaking, the largest element of the sequence is guaranteed to end up as the last term, which is where it should be. This largest element is called the largest bubble. We shake the array, and the largest bubble ends up at the top.
After the second shaking, the next largest element (which is called the second largest bubble) will end up in its correct position. After \((N-1)\)-th shaking, the second smallest element takes its correct position. Consequently, the smallest element also must be in its place after \(N-1\) shakings.
Each shaking consists of one passage through the sequence from left to right. The passage visits every pair of adjacent elements, and swaps them whenever their order is not correct.
The entire program is given below.
#include<iostream>
void swap(long& a, long& b){
long temp=a; a=b; b=temp;
}
void bSort(long* aX, long n){
long shaking=0; long step;
while(shaking<n-1){
step=0;
while(step<n-1-shaking){
if(aX[step]>aX[step+1]){swap(aX[step],aX[step+1]);}
++step;
}
++shaking;
}
}
void printSequence(long* aX, long n){
long i=0;
while(i<n){std::cout<<aX[i]<<" ";++i;}
std::cout<<"\n";
}
int main(){
long* aX;long n; std::cin>>n;
if(n<8){n=8;}
aX=new long[n];
for(long i=0;i<n;++i){
std::cin>>aX[i];
}
bSort(aX,n);
printSequence(aX,n);
delete[] aX;
return 0;
}
4. Merge sort

Merge sort has complexity \(O(N\log N)\), where \(N\) is the length of the sequence. The algorithm consists of the following four steps:
- Step 1. Divide sequence into two parts: Left and Right. The two parts should be of the same size or have their sizes differ by \(1\).
- Step 2. Sort the left (using merge sort).
- Step 3. Sort the right (using merge sort).
- Step 4. Merge the two sorted sequences.
Merging two sorted sequences can be done with one passage through the sequence.
#include<iostream>
void mTwoSortedSeq(long* sA, long* sB, long* sM, long k, long l){
long wA=0, wB=0, wM=0;
while( (wA < k) || (wB < l) ){
if(wA==k){
sM[wM]=sB[wB]; ++wB; ++wM;
}
else{
if(wB==l){
sM[wM]=sA[wA]; ++wA; ++wM;
}
else{
if(sA[wA] < sB[wB]){
sM[wM]=sA[wA]; ++wA; ++wM;
}
else{
sM[wM]=sB[wB]; ++wB; ++wM;
}
}
}
}
}
void mergeSort(long* seq, long n){
if(n > 1){
//Step 1: Divide
long m=n/2;
//Step 2: Sort left
mergeSort(seq,m);
//Step 3: Sort right
mergeSort(seq+m,n-m);
//Step 4: Merge
long* sM=new long[n];
//The same as: long* sM; sM=new long[n];
mTwoSortedSeq(seq,seq+m,sM,m,n-m);
// m is the length of the "left" sorted seq,
// whose pointer to the first term is seq;
// n-m is the length of the "right" sorted sequence,
// whose pointer to the first term is (seq+m)
// Final steps: Copy the sequence sM into seq
for(long i=0;i < n;++i){seq[i]=sM[i];}
// Prevent memory leak:
delete[] sM;
}
}
int main(){
long n;
std::cin>>n;
long* x;
x=new long[n];
for(long i=0;i < n;++i){
std::cin>>x[i];
}
mergeSort(x,n);
std::cout<<"Sorted sequence is \n";
for(long i=0;i < n;++i){
std::cout<< x[i] << " ";
}
std::cout<< "\n";
delete[] x;
return 0;
}
5. Practice problems
Create a function that finds the index i of the term in the non-decreasing sequence that is closest to the given number key. The complexity of the algorithm should be \(O(\log n)\), where \(n\) is the length of the sequence. The arguments of the function are the pointer to the block of memory that contains the given non-decreasing sequence of integers, the length of the sequence, and the integer key.
Examples: Assume that the sequence has length n=10 and that the terms are
11 21 31 41 51 61 71 81 91 101.If
key=1, then the function should return \(0\), because x[0]=11 is the closest term to the number 1. If key=73, then the function should return \(6\), because x[6]=71 is the closest term to 73. If key=77, then the function should return \(7\). If key=76, then your function is allowed to return either \(6\) or \(7\).
The user input consists of an integer n, a sequence x of n integers, and an integer M. Create a program that identifies two terms from the sequence x whose sum is closest to M. If there are several pairs of integers from x whose sum is closest to M, the program can choose any of them. The complexity of the program should be at most \(O(n\log n)\).
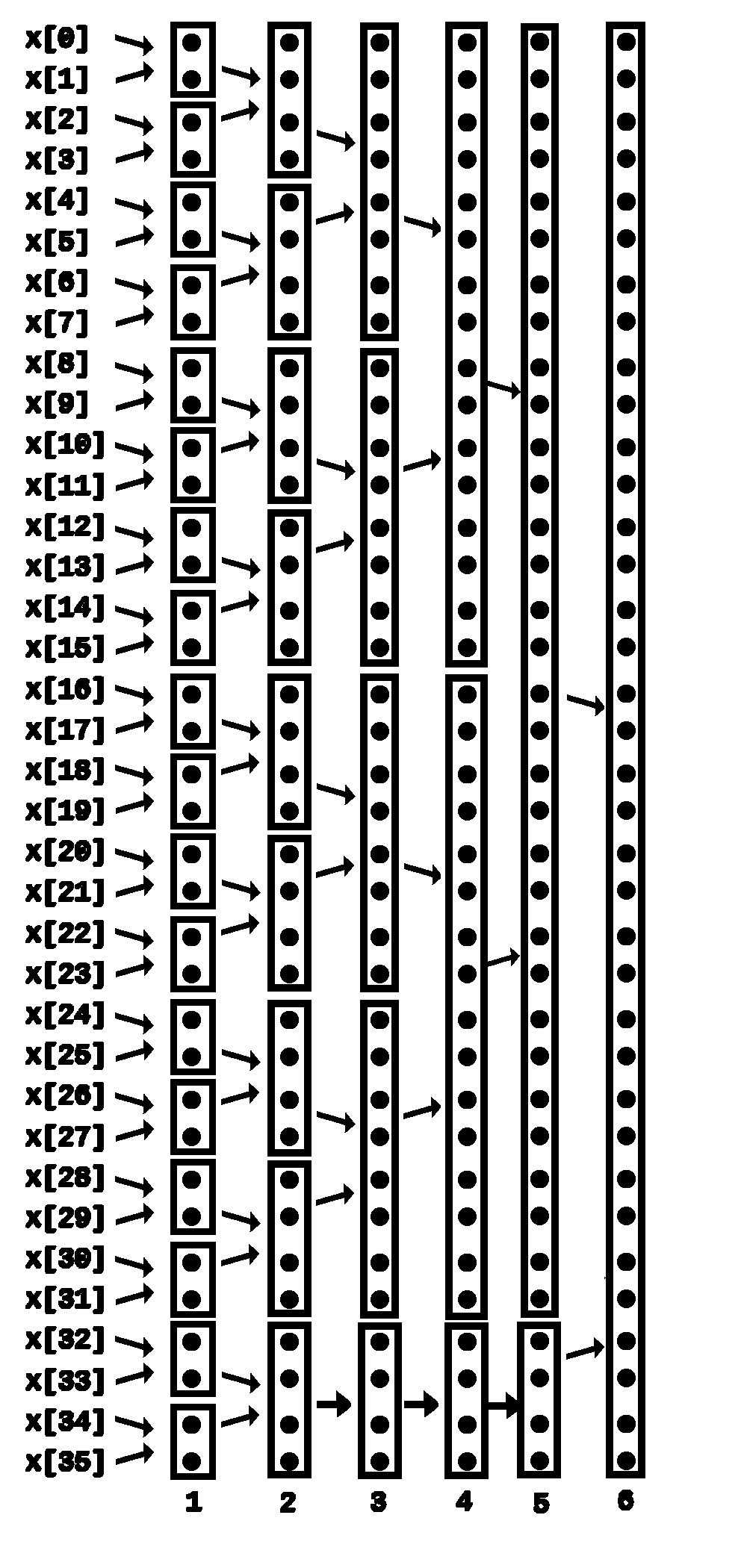
The non-recursive implementation of the merge sort algorithm applied to the sequence x[0], x[1], x[2], \(\dots\) can be divided into steps. In the first steps, the entire sequence is divided into blocks of size \(2\) and each of these blocks is sorted. In the second step, the adjacent blocks of size \(2\) are merged and the new blocks of size \(4\) are obtained. In the step \(3\), the sorted blocks from step \(2\) are now merged into sorted blocks of size \(8\), etc. The user input consists of non-negative integers \(i\) and \(j\). Create the program that determines the step in which the terms \(x[i]\) and \(x[j]\) will end up in the same block for the first time.